
0x00 说明
最近在学习爬虫,自己写了两个小爬虫来练手,这里放出代码
0x01 爬虫代码
豆瓣前250图书
spider:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39from douban_book.items import DoubanBookItem
from scrapy import Request
from scrapy.spiders import Spider
import scrapy
class DoubanSpider(Spider):
name = 'doubanbook'
start_urls = {'https://book.douban.com/top250'}
'''
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36',
}
def start_requests(self):
url = 'https://book.douban.com/top250'
yield Request(url, headers=self.headers)
'''
def parse(self, response):
item = DoubanBookItem() #实例化Item
books = response.xpath('//div[@class="indent"]/table')
print(books)
print('*******************************************************')
for book in books:
item['book_name'] = book.xpath(
'.//div[@class="pl2"]/a/text()').extract()[0]
item['book_author'] = book.xpath(
'.//td/p[@class="pl"]/text()').extract()[0]
item['book_star'] = book.xpath(
'.//div[@class="star clearfix"]/span[2]/text()').extract()[0]
item['book_jianjie'] = book.xpath(
'.//p[@class="quote"]/span/text()').extract()[0]
item['book_num'] = book.xpath(
'.//div[@class="star clearfix"]/span[3]/text()').re(r'(\d+)人评价')[0]
yield item
next_url = response.xpath('//span[@class="next"]/a/@href').extract() #实现翻页功能
if next_url:
next_url = next_url[0]
yield Request(next_url)
然后将items.py改为:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class DoubanBookItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
#书名
book_name = scrapy.Field()
#书的作者
book_author = scrapy.Field()
#书的简介
book_jianjie = scrapy.Field()
#书的评分
book_star = scrapy.Field()
#评价人数
book_num = scrapy.Field()
豆瓣前250电影
1 | from scrapy import Request |
然后将items.py改为1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class DoubanMovieItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 排名
ranking = scrapy.Field()
# 电影名称
movie_name = scrapy.Field()
# 评分
score = scrapy.Field()
# 评论人数
score_num = scrapy.Field()
# 电影简介
movie_quote = scrapy.Field()
0x03总结
一开始这两个脚本改了很久,一直出现只能爬取每页的第一个电影/书籍,怎么改都不能爬到全部的内容。
错误分析(豆瓣图书)
之前我的books是这样定义的books = response.xpath('//div[@class="indent"]'),就只能爬取到每页第一个。探索了很久,改了之后books = response.xpath('//div[@class="indent"]/table')这里放出节点的图片,就自然理解了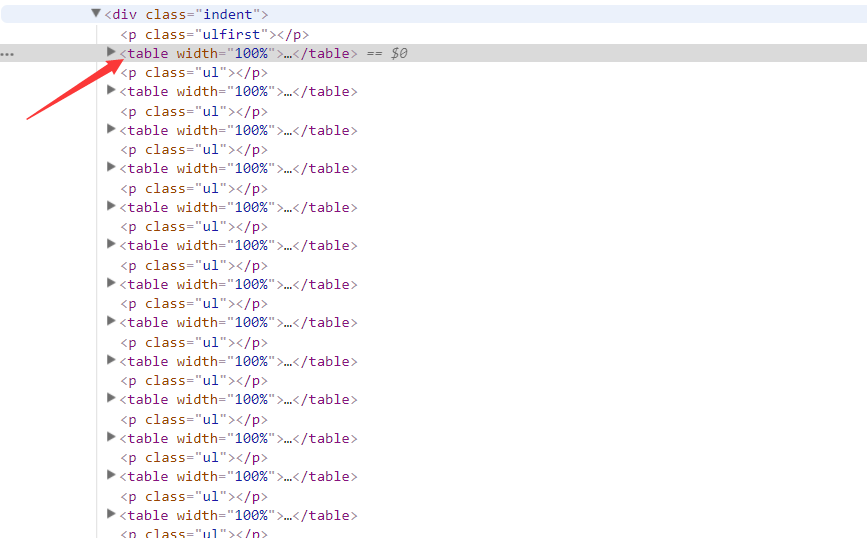
其中所有信息都放在table下面,所以必须要把table加上,是他们共同的父节点。